
Getting Champion Coordinates from the LoL Minimap using Deep Learning
Using a GAN and a ConvLSTM to go from minimap from to champion coordinates: This post was originally published on Medium.
At PandaScore, we built a model to track the positions of each champion in a League of Legends (LoL) game, based solely on images of the minimap. In this more technical blog post, we describe how we achieved this.
Background
PandaScore is the provider of static and real-time data for eSports. We cover a range of video games and tournaments, converting live in-game action into usable data for our customers. These customers range from media outlets, to betting market providers, to eSports teams themselves.
A core part of the work we do involves deep learning and computer vision. This is needed as we take video streams of live eSports matches, and convert them into data describing what is happening in the game.
The League of Legends (LoL) minimap is a great example of this work. For this particular task, our specific goal was to build an algorithm that can ‘watch’ the minimap, and output the (x, y) coordinates of each player on the minimap.
We saw creating this model as a high priority for our customers. Knowing the coordinates of each player in each moment of every game opens up a multitude of possibilities. The information could, for example, allow teams to better understand the effectiveness of their play strategies. It could be also be used to predict when certain events are going to happen in a game. Or it could be used to make more engaging widgets for spectators, with real-time stats.
Our customers expect the data we provide to be extremely accurate. Building a model that would be sufficiently reliable was far from an easy task however. We describe why in the next section.
The Problem
In the deep learning literature, the type of problem that involves looking at images and locating or tracking objects in that image is generally referred to as object detection, or tracking.
On the surface, our particular minimap problem appears as though it could be easily solved with detection models such as YOLO or SSD. We would just need to label a large dataset of minimap crops with the positions of each champion, and then pass this dataset to one of these algorithms.
Indeed, this was the approach we tried first. Drawing on previous work on the LoL minimap problem done by Farzain Majeed in his DeepLeague project, we trained an SSD-style model on Farza’s DeepLeague100K dataset, and found it to work quite well on a held-out test set from his dataset.
There was one major problem with this approach however: the model did not generalise to champions not present in the dataset that it was trained on. We needed a model that would work for any champion a player happens to choose — a model that pushes errors if player chooses a rarely-picked or new champion would not be acceptable for customers of PandaScore.
We spent some weeks exploring a number of routes to resolving this issue. The main options were:
-
Manually annotate a lot more training data: we ruled this out as it would be too time-consuming to perform and maintain.
-
Train a model to detect the positions of any champion on the minimap, then feed the detected regions from this model to a classifier model covering all champions: this approach showed some promise early on, but was ultimately deemed unworkable.
-
Train a model on the raw champion ‘portraits’ **— the raw portrait images of each champion that the icons on the minimap are based on — then somehow **transfer this model to work in detecting the champions on real minimap frames.
We ultimately went with approach 3, which we describe in more detail in the next section.
The Approach
The final approach we arrived at relied on a classifier that was trained on the raw champion portraits. If the classifier was only trained on these portraits, then we could be more certain that it would not give any preferential treatment to the champions that only occur in our minimap frames/hero coordinates training dataset.
The general idea here is to train a classifier on heavily-augmented versions of the raw champion portraits. We could then slide this trained classifier over minimap frames, resulting in a grid of predictions. At each square in this grid, we could extract the detection probabilities for each of the 10 champions we know are being played in the current game. These detection grids could then be fed to a second, champion-agnostic model that would learn to clean these up and output the correct (x, y) coordinates for each detected champion.
For the classifier however, we found that standard (albeit heavy) augmentation was insufficient to train a model on raw champion portraits that could reliably generalise to the champions as they appear on the minimap. We needed augmentations that could transform the raw portraits, such that they looked the same as they do on the minimap.

On the minimap, LoL champions appear with a blue or red circle around them. There can be explosions, pings, and other artifacts that also obfuscate the portraits. We experimented with crudely adding such artifacts manually. We found however, that the most effective approach was to learn a model that could generate such artifacts. We achieved this with a Generative Adversarial Network (GAN). In short, GANs are a neural network-based approach that allows us to learn a model that can generate data from a desired distribution (in our case, we essentially want to generate explosions, pings, blue or red circles, and other artifacts to add to the raw champion portraits). A general introduction to GANs can be found here.
Training the GAN
Our particular use of GANs differs somewhat from the usual setup. We couldn’t just generate champion images in the minimap environment directly, as if we did this, our model would only learn to generate the around 50 out of 140 champions that are present in our minimap frames dataset.
Rather, in our case we needed to generate masks to add to raw champion portraits. The discriminator of the GAN would thus see the raw champion portrait plus the mask, and the generator would have to learn to change these masks such that the combination looks real. This is illustrated in the diagram below.

As the generator’s adversary, the discriminator tries to distinguish between ‘real’ images (crops of hero images taken directly from minimap frames), and ‘fake’ images (generated masks added to random hero portraits). After much tweaking effort and training time, we were able to train a mask-generating generator, which we put to use in the next section.
Training the Classifier
We now had a trained generator that was capable of producing masks that, when added to any raw champion portrait, would take us to a distribution of images that look (somewhat) like how that champion might appear on the minimap. We could thus train a classifier on this distribution, in the hopes that it would also work for detecting champions on real minimap frames.
The below diagram illustrates the training setup for this classifier:

This step is quite simple really. We just train an ordinary convolutional neural network (convnet) classifier C on our raw champion portraits, augmented by the GAN-generated masks. We use a shallow, wide classifier network with lots of dropout to prevent overfitting to the GAN-style data.
Calculating the detection maps
Our classifier is a fully-convolutional neural network that takes colour 24x24 ‘champion-on-the-minimap’ images as input and outputs a 1x1x(NumChampions + 1) tensor. We pass this tensor through a softmax nonlinearity to estimate class probabilities (the additional output channel is for a background class; we trained our classifier to also detect random patches of minimap with no champion and output a high ‘background’ probability).
If we instead pass an entire minimap crop of size 296x296 to this classifer, we get a 12x12x(NumChampions + 1) output. Each square of this 12x12 grid represents a region of the minimap, and in each of these squares we have the detection probabilities for each champion. We can increase the resolution of this ‘detection map’ to 70x70 by reducing the stride of the final two layers of our classifier (a convolution layer followed by an average pooling layer) to 1, from 2 (this trick has been applied elsewhere, e.g. in this work).
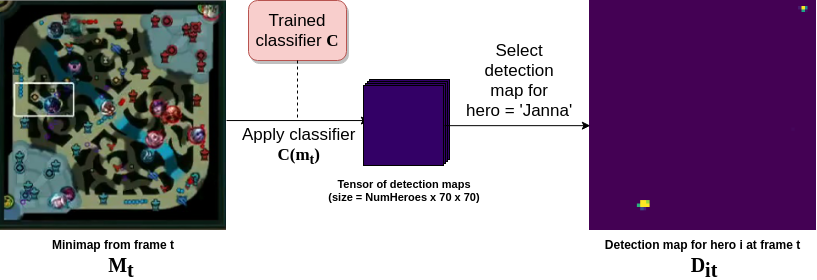
We slice out these ‘detection maps’ — as shown above— for each of the ten champions present in the current game. We also slice out the detection map for the background class. This 70x70x11 tensor then serves as the input to the final stage in our minimap model — a convolutional LSTM sequence model.
Training the sequence model
Very often, when champions are close to one another, one champion’s icon on the minimap will cover that of another. This poses issues for our classifier from the previous step, which cannot detect the champion that is being covered. As our customers rely upon the accuracy of our data feeds, we needed to address this issue. To do so, we enlisted a sequence model.
The idea here is that a sequence model can have some ‘memory’ of where the champions were last seen, and if they disappear suddenly, and another champion is nearby, then our model can ‘assume’ that the missing champion is probably just behind the nearby champion.
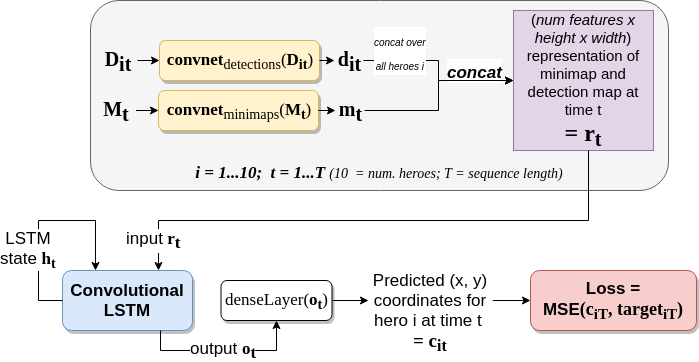
The above diagram presents the architecture of our sequence model. We take the 11 detection maps (D_it) extracted as described in the previous section (ten champions + one background), and pass each independently through the same convnet, which reduces their resolution and extracts relevant information. A low resolution copy of the minimap crop itself (M_t) is also passed through a separate convnet, the idea being that some low-resolution features about what is going on in the game might also be useful (e.g. if there is a lot of action, then non-detected champions are likely just hidden among that action).
The minimap and detection map features extracted from these convnets are then stacked into a single tensor of shape 35x35xF, where F is the total number of features (the minimap and detection map inputs were of size 70x70, and our convnets halved this resolution). We call this tensor r_t in the above diagram, as we have one of these tensors at each time step. These r_t are then fed sequentially into a convolutional LSTM (see this paper for conv-LSTM implementation details). We found switching from a regular LSTM to a convolutional LSTM to be hugely beneficial. Presumably, this was because the regular LSTM needed to learn the same ‘algorithm’ for each location on the minimap, whereas the conv-LSTM allowed this to be shared across locations.
At each time step, each of the convolutional LSTM’s 10 output channels (o_it, one i for each champion) is passed through the same dense (fully-connected) layer. This then outputs x and y coordinates for each champion. The mean squared error (MSE) between the output and target coordinates is then backpropagated to the weights of this network. The model converges after 6 or so hours of training on a single GPU (we trained on our own dataset of around 80 games, that was obtained in a similar way to that described by Farza).
Results
We are still more rigourously evaluating our network before moving it into production. However results on our in-house test set suggest that more than 95% of all detections are within a 20 pixel radius of the target. Out of interest, we also tested the necessity of the GAN augmentation, but found performance to be substantially degraded when using standard augmentation alone, as opposed to augmenting with the GAN-generated masks. So it seems all our GAN training was not for nothing :)
This article is quite light on implementation details, and we’re sure some of our more technical readers will want to know more. If you have questions, please don’t hesitate to ask them here in the comments, or in the r/machinelearning thread.